{{ item.activity_start_time }}
{{ item.activity_city }}

我们在图像、视频和文本的生成人工智能方面看到了很多令人兴奋的AI生成工具,但音频似乎总是有点落后。Meta 近日推出了名为 AudioCraft 的开源人工智能工具,该工具将帮助用户根据文本提示创建音乐和音频。
近年来,包括语言模型在内的生成式人工智能模型取得了巨大进步,并显示出非凡的能力。尽管我们在图像、视频和文本的生成人工智能方面看到了很多令人兴奋的AI生成工具,但音频似乎总是有点落后。
Meta 近日推出了名为 AudioCraft 的开源人工智能工具,该工具将帮助用户根据文本提示创建音乐和音频。
AudioCraft 包含三个模型:MusicGen、AudioGen和EnCodec。MusicGen 使用 Meta 拥有且专门授权的音乐进行训练,根据基于文本的用户输入生成音乐,而 AudioGen 使用公共音效进行训练,根据基于文本的用户输入生成音频。
现在,Meta发布了 EnCodec 解码器的改进版本,它可以用更少的音损生成更高质量的音乐;我们预先训练的 AudioGen 模型,可让您生成环境声音和声音效果,例如狗叫声、汽车喇叭声或木地板上的脚步声;以及所有 AudioCraft 模型权重和代码。这些模型可用于研究目的并加深人们对该技术的理解。
MusicGen 是专门为音乐生成量身定制的音频生成模型。音乐曲目比环境声音更复杂,在创建新颖的音乐作品时,在长期结构上生成连贯的样本尤其重要。MusicGen 接受了大约 400,000 个录音以及文本描述和元数据的训练,总计 20,000 小时的音乐,这些音乐由 Meta 拥有或专门为此目的获得许可。
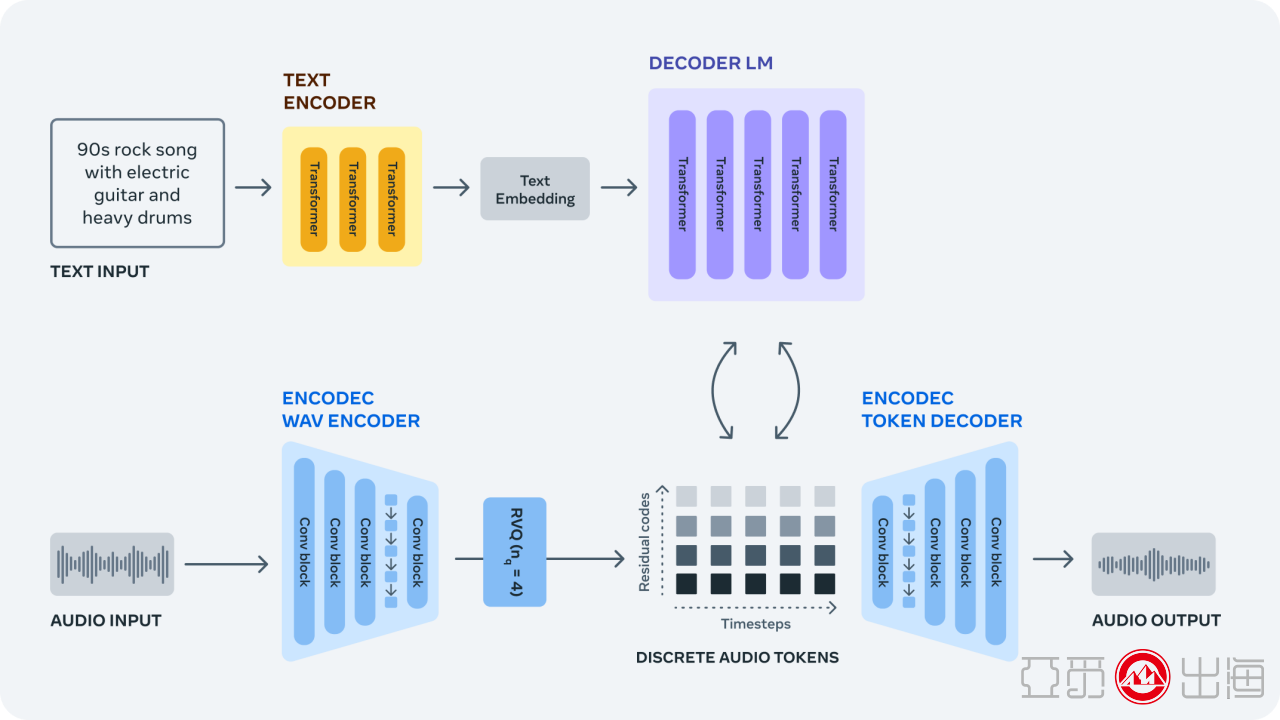
AudioCraft工作流程 图片来源:Meta

【原创申明】为了更好保护支持原创内容和对忠实读者负责,本网站跨境阿米SHOW(网站地址:www.amishow.com)及公众号跨境阿米SHOW(微信号:amishow321)刊载的包括文字、图片、音频、视频等所有内容,除签署正式付费转载协议伙伴外,禁止任何形式的复制、转载、修改或者以其他方式使用本网站或本公众号的内容。本网站或本公众号部分引用资料只代表原作者意见,不代表本网站www.amishow.com或者本公众号『跨境阿米SHOW』任何立场,如发现本站文字存在版权疑问,请联系我们「微信号:amishow01」「邮箱copyright@amishow.com」处理。
Copyright © 2013-2025 @米Show 粤ICP备19000957号-1 地址:广州市天河区车陂大岗路2号联合社区西区6号楼305单元

发表评论
请先登录后参与评论
{{ item.user_info.display_name }}